 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchWorld: Gradient-Free Optimization of Executable World Models
May 29, 2026Text-agent environments are typically modeled as partially observable Markov decision processes (POMDPs), assuming that the simulator's latent state and transition dynamics are hidden from the agent. Yet little work has examined whether executable code can be induced to serve as a world model for prediction and planning under partial observability. We introduce PatchWorld, a gradient-free framework that turns offline trajectories into executable Python world models through counterexample-guided code repair. Instead of predicting the next observation with a black-box model, PatchWorld induces symbolic belief-state programs whose action updates can be inspected, replayed, and locally patched. Across seven AgentGym environments, PatchWorld-Simple achieves the highest code-based planning score among evaluated methods, reaching 76.4\% macro success in live one-step lookahead while invoking no LLM calls inside the world-model prediction module itself. We further find that a human-specified residual-memory bias improves surface observation fidelity but weakens decision utility. This exposes a tradeoff in executable world models, since improving observation fidelity can come at the expense of action-discriminative dynamics, and vice versa. Code is available at https://github.com/HKBU-KnowComp/PatchWorld.
KGPFN: Unlocking the Potential of Knowledge Graph Foundation Model via In-Context Learning
May 14, 2026Knowledge graph (KG) foundation models aim to generalize across graphs with unseen entities and relations by learning transferable relational structure. However, most existing methods primarily emphasize relation-level universality, while in-context learning, the other pillar of foundation models remains under-explored for KG reasoning. In KGs, context is inherently structured and heterogeneous: effective prediction requires conditioning on the local context around the query entities as well as the global context that summarizes how a relation behaves across many instances. We propose KGPFN, a KG foundation model using Prior-data Fitted Network that unifies transferable relational regularities with inference-time in-context learning from structured context. KGPFN first learns relation representations via message passing on relation graphs to capture cross-graph relational invariances. For query-specific reasoning, it encodes local neighborhoods using a multi-layer NBFNet as local context. To enable ICL at global scale, it constructs relation-specific global context by retrieving a large set of instances of the query relation together with their local neighborhoods, and aggregates them within a Prior-Data Fitted Network framework that combines feature-level and sample-level attention. Through multi-graph pretraining on diverse KGs, KGPFN learns when to instantiate reusable patterns and when to override them using contextual evidence. Experiments on 57 KG benchmarks demonstrate that KGPFN achieves strong adaptation to previously unseen graphs through in-context learning alone, consistently outperforming competitive fine-tuned KG foundation models. Our code is available at https://github.com/HKUST-KnowComp/KGPFN.
DeepRefine: Agent-Compiled Knowledge Refinement via Reinforcement Learning
May 11, 2026Agent-compiled knowledge bases provide persistent external knowledge for large language model (LLM) agents in open-ended, knowledge-intensive downstream tasks. Yet their quality is systematically limited by \emph{incompleteness}, \emph{incorrectness}, and \emph{redundancy}, manifested as missing evidence or cross-document links, low-confidence or imprecise claims, and ambiguous or coreference resolution issues. Such defects compound under iterative use, degrading retrieval fidelity and downstream task performance. We present \textbf{DeepRefine}, a general LLM-based reasoning model for \emph{agent-compiled knowledge refinement} that improves the quality of any pre-constructed knowledge bases with user queries to make it more suitable for the downstream tasks. DeepRefine performs multi-turn interactions with the knowledge base and conducts abductive diagnosis over interaction history, localizes likely defects, and executes targeted refinement actions for incremental knowledge base updates. To optimize refinement policies of DeepRefine without gold references, we introduce a Gain-Beyond-Draft (GBD) reward and train the reasoning process end-to-end via reinforcement learning. Extensive experiments demonstrate consistent downstream gains over strong baselines.
SpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
Mar 24, 2026Agentic multimodal large language models (MLLMs) (e.g., OpenAI o3 and Gemini Agentic Vision) achieve remarkable reasoning capabilities through iterative visual tool invocation. However, the cascaded perception, reasoning, and tool-calling loops introduce significant sequential overhead. This overhead, termed agentic depth, incurs prohibitive latency and seriously limits system-level concurrency. To this end, we propose SpecEyes, an agentic-level speculative acceleration framework that breaks this sequential bottleneck. Our key insight is that a lightweight, tool-free MLLM can serve as a speculative planner to predict the execution trajectory, enabling early termination of expensive tool chains without sacrificing accuracy. To regulate this speculative planning, we introduce a cognitive gating mechanism based on answer separability, which quantifies the model's confidence for self-verification without requiring oracle labels. Furthermore, we design a heterogeneous parallel funnel that exploits the stateless concurrency of the small model to mask the stateful serial execution of the large model, maximizing system throughput. Extensive experiments on V* Bench, HR-Bench, and POPE demonstrate that SpecEyes achieves 1.1-3.35x speedup over the agentic baseline while preserving or even improving accuracy (up to +6.7%), thereby boosting serving throughput under concurrent workloads.
NGDB-Zoo: Towards Efficient and Scalable Neural Graph Databases Training
Feb 25, 2026Neural Graph Databases (NGDBs) facilitate complex logical reasoning over incomplete knowledge structures, yet their training efficiency and expressivity are constrained by rigid query-level batching and structure-exclusive embeddings. We present NGDB-Zoo, a unified framework that resolves these bottlenecks by synergizing operator-level training with semantic augmentation. By decoupling logical operators from query topologies, NGDB-Zoo transforms the training loop into a dynamically scheduled data-flow execution, enabling multi-stream parallelism and achieving a $1.8\times$ - $6.8\times$ throughput compared to baselines. Furthermore, we formalize a decoupled architecture to integrate high-dimensional semantic priors from Pre-trained Text Encoders (PTEs) without triggering I/O stalls or memory overflows. Extensive evaluations on six benchmarks, including massive graphs like ogbl-wikikg2 and ATLAS-Wiki, demonstrate that NGDB-Zoo maintains high GPU utilization across diverse logical patterns and significantly mitigates representation friction in hybrid neuro-symbolic reasoning.
Egocentric Gaze Estimation via Neck-Mounted Camera
Feb 12, 2026This paper introduces neck-mounted view gaze estimation, a new task that estimates user gaze from the neck-mounted camera perspective. Prior work on egocentric gaze estimation, which predicts device wearer's gaze location within the camera's field of view, mainly focuses on head-mounted cameras while alternative viewpoints remain underexplored. To bridge this gap, we collect the first dataset for this task, consisting of approximately 4 hours of video collected from 8 participants during everyday activities. We evaluate a transformer-based gaze estimation model, GLC, on the new dataset and propose two extensions: an auxiliary gaze out-of-bound classification task and a multi-view co-learning approach that jointly trains head-view and neck-view models using a geometry-aware auxiliary loss. Experimental results show that incorporating gaze out-of-bound classification improves performance over standard fine-tuning, while the co-learning approach does not yield gains. We further analyze these results and discuss implications for neck-mounted gaze estimation.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025



We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
Prompt as Knowledge Bank: Boost Vision-language model via Structural Representation for zero-shot medical detection
Feb 22, 2025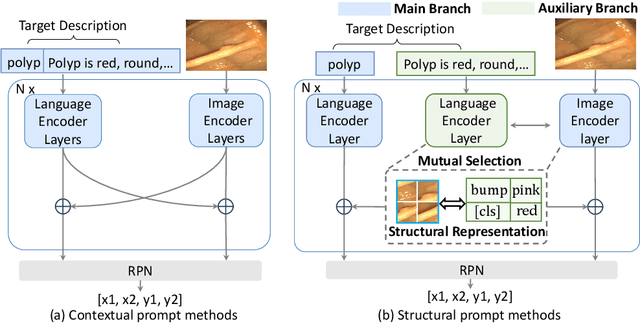
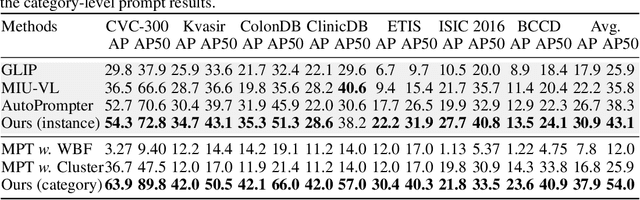
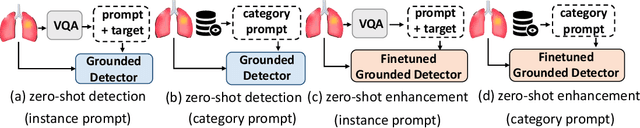
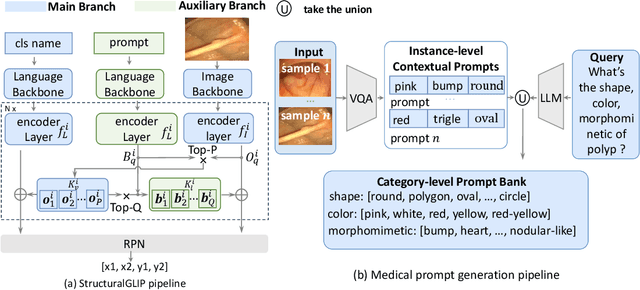
Zero-shot medical detection can further improve detection performance without relying on annotated medical images even upon the fine-tuned model, showing great clinical value. Recent studies leverage grounded vision-language models (GLIP) to achieve this by using detailed disease descriptions as prompts for the target disease name during the inference phase. However, these methods typically treat prompts as equivalent context to the target name, making it difficult to assign specific disease knowledge based on visual information, leading to a coarse alignment between images and target descriptions. In this paper, we propose StructuralGLIP, which introduces an auxiliary branch to encode prompts into a latent knowledge bank layer-by-layer, enabling more context-aware and fine-grained alignment. Specifically, in each layer, we select highly similar features from both the image representation and the knowledge bank, forming structural representations that capture nuanced relationships between image patches and target descriptions. These features are then fused across modalities to further enhance detection performance. Extensive experiments demonstrate that StructuralGLIP achieves a +4.1\% AP improvement over prior state-of-the-art methods across seven zero-shot medical detection benchmarks, and consistently improves fine-tuned models by +3.2\% AP on endoscopy image datasets.
Can LLMs be Good Graph Judger for Knowledge Graph Construction?
Nov 26, 2024



In real-world scenarios, most of the data obtained from information retrieval (IR) system is unstructured. Converting natural language sentences into structured Knowledge Graphs (KGs) remains a critical challenge. The quality of constructed KGs may also impact the performance of some KG-dependent domains like GraphRAG systems and recommendation systems. Recently, Large Language Models (LLMs) have demonstrated impressive capabilities in addressing a wide range of natural language processing tasks. However, there are still challenges when utilizing LLMs to address the task of generating structured KGs. And we have identified three limitations with respect to existing KG construction methods. (1)There is a large amount of information and excessive noise in real-world documents, which could result in extracting messy information. (2)Native LLMs struggle to effectively extract accuracy knowledge from some domain-specific documents. (3)Hallucinations phenomenon cannot be overlooked when utilizing LLMs directly as an unsupervised method for constructing KGs. In this paper, we propose GraphJudger, a knowledge graph construction framework to address the aforementioned challenges. We introduce three innovative modules in our method, which are entity-centric iterative text denoising, knowledge aware instruction tuning and graph judgement, respectively. We seek to utilize the capacity of LLMs to function as a graph judger, a capability superior to their role only as a predictor for KG construction problems. Experiments conducted on two general text-graph pair datasets and one domain-specific text-graph pair dataset show superior performances compared to baseline methods. The code of our proposed method is available at https://github.com/hhy-huang/GraphJudger.
VersusDebias: Universal Zero-Shot Debiasing for Text-to-Image Models via SLM-Based Prompt Engineering and Generative Adversary
Jul 28, 2024



With the rapid development of Text-to-Image models, biases in human image generation against demographic groups social attract more and more concerns. Existing methods are designed based on certain models with fixed prompts, unable to accommodate the trend of high-speed updating of Text-to-Image (T2I) models and variable prompts in practical scenes. Additionally, they fail to consider the possibility of hallucinations, leading to deviations between expected and actual results. To address this issue, we introduce VersusDebias, a novel and universal debiasing framework for biases in T2I models, consisting of one generative adversarial mechanism (GAM) and one debiasing generation mechanism using a small language model (SLM). The self-adaptive GAM generates specialized attribute arrays for each prompts for diminishing the influence of hallucinations from T2I models. The SLM uses prompt engineering to generate debiased prompts for the T2I model, providing zero-shot debiasing ability and custom optimization for different models. Extensive experiments demonstrate VersusDebias's capability to rectify biases on arbitrary models across multiple protected attributes simultaneously, including gender, race, and age. Furthermore, VersusDebias outperforms existing methods in both zero-shot and few-shot situations, illustrating its extraordinary utility. Our work is openly accessible to the research community to ensure the reproducibility.